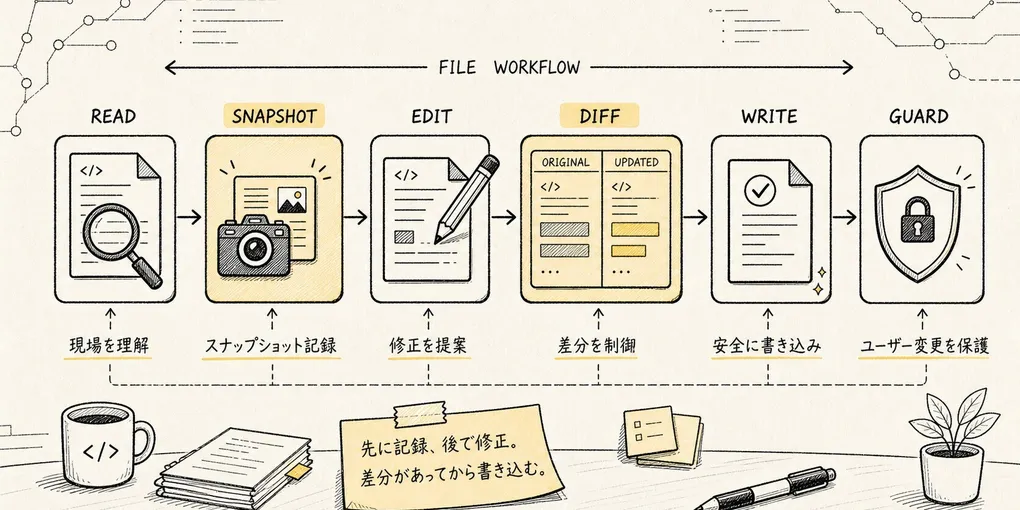
Claude Code ソースコード解説シリーズ 第7章: ファイルツール
Claude Code が実際のコードベース内でファイルを安全に読み書きする方法を見ていきます。
『Claude Code ソースコード解析シリーズ』第7章|ファイルツール
AI にバグ修正を頼んだら、「はい、ファイルを更新しました」と一言。
開いてみると、さっき手で入れたコメントがすべて消えている。
これこそが Agent によるコード変更の最も恐ろしいところだ。Agent は人間のように「ファイルが以前どうなっていたか」を覚えていないし、「さっきこの行をいじったかどうか」にも気づかない。Claude Code がこの問題を解決するために用意したのが、一見もっとも地味に見えるファイルツール群——Read、Edit、Write だ。
名前はたしかに平凡そのものだ。
Read:ファイルを読む。Edit:文字列置換でファイルを変更する。Write:ファイルを新規作成または全体を上書きする。NotebookEdit:Jupyter Notebook 専用の編集。
名前だけ聞けば、シェルコマンドの薄いラッパーに思えるだろう。
Read ~= cat
Edit ~= sed
Write ~= echo > fileしかしソースコードにおいて本当に興味深いのは、まさに「そういう理解をモデルにさせたくない」という Claude Code の明確な設計意図が表れている点だ。
packages/builtin-tools/src/tools/BashTool/prompt.ts では、Bash ツールがモデルに対して次のように注意を促している。
Read files: Use Read (NOT cat/head/tail)
Edit files: Use Edit (NOT sed/awk)
Write files: Use Write (NOT echo >/cat <<EOF)この文言の背後にある設計判断は極めて率直だ。
ファイル操作はただの I/O ではない。Agent が「コードを観察する」段階から「コードを変える」段階へと踏み越える、その境界なのだ。
人間のエンジニアにとって、ファイルを開き、一行書き換え、保存する——これはきわめて自然な動作だ。しかし Agent にとっては、システムが面倒を見なければならないいくつかの問題がここに潜んでいる。
- Agent は本当にそのファイルを読んだのか?
- 読んだ内容は最新のものか?
- 置換しようとしている文字列は一意に特定できるか?
- 読み取ったあとにユーザやフォーマッターがファイルを変更していないか?
- 今回の変更は diff として表示できるか?
- 変更前に復元可能な履歴スナップショットはあるか?
- 変更後、LSP、VSCode、診断システムに通知する必要はあるか?
この記事で答えようとしている中心的な問いは、「Claude Code はどうやってファイルを読み書きするのか」ではない。
本当の問いは:Claude Code はどのようにしてモデルにコードを変更させながら、読み間違い・修正ミス・他者による変更の上書きを可能な限り防いでいるのか?
前回までの例を引き続き使おう。
ユーザー:ログイン失敗の問題を修正して。信頼できるファイル操作の流れとは、モデルがいきなりファイルを推測で決めて上書きするようなものではなく、次のようになるべきだ。
Glob / Grep でまず範囲を絞り込む
-> Read で候補ファイルを読み取り、内容のベースラインを確立する
-> Edit で一意な文字列を用いた局所的な置換を行う
-> Write は新規ファイルの作成または完全な書き換え時にのみ使う
-> ツール層が diff を生成し、readFileState を更新し、LSP / VSCode に通知する
-> Bash でテストを実行し結果を検証する
これが、エージェントシステムにおけるファイルツールの位置づけである。すなわち、単なる「ファイル API」ではなく、ファイルの読み書きを中心に構築された安全なワークフローなのだ。
1. なぜ Bash で直接ファイルを読み書きしないのか
最も原始的なやり方はシンプルだ。モデル自身にシェルを組ませる。
cat src/auth.ts
sed -i 's/old/new/g' src/auth.ts
cat <<EOF > src/auth.ts
...
EOF一見すると実務のエンジニアの日常操作そのものだが、Agent ランタイムに載せると問題が生じる。
1. シェルコマンドは「操作の種類」を表現できない
同じ Bash の断片であっても、
cat src/auth.tsこれは読み取り操作。
sed -i 's/foo/bar/g' src/auth.tsこれは書き込み操作。
node scripts/migrate.jsこれは読み取りかもしれないし、書き込みかもしれないし、データベースに接続するかもしれない。
すべてのアクションが Bash の中に混在していると、Claude Code がツール層で次のような判断を下すのが難しくなる。
- これは読み取りか、書き込みか
- 並行実行できるか
- 権限の確認が必要か
- diff を表示すべきか
- 既読ファイルキャッシュを更新すべきか
- ファイル履歴を記録すべきか
専用ファイルツールの価値は、まずこれらのアクションをプロトコル化することにある。
2. シェルコマンドはファイルツールの状態管理を迂回してしまう
ファイル編集で最も怖いのは「書き込み失敗」ではない。「書き込みは成功したが、上書きしてはいけない内容を上書きした」ことだ。
例を示す。
1. Agent が src/auth.ts を読んだ
2. ユーザーが手動で src/auth.ts を変更した
3. Agent が古い内容を元に書き戻した
4. ユーザーが先ほど加えた変更が上書きされたAgent が sed や echo > file を使う場合、ツールシステムからはひとつのコマンドしか見えない。実際にどのファイルを変更したのか、変更前の内容は何か、変更後に読み取りキャッシュを更新すべきか、といった情報を把握するのが非常に難しい。
一方、Read / Edit / Write は、ファイルパス、元の内容、変更後の内容、mtime、diff をすべてツールプロトコルに取り込む。これにより、Claude Code は「読んでから変更する」フローや「ダーティライト防止」を実現できる。
3. ファイル操作はモデル向けとユーザー向けの二系統の出力を必要とする
モデルが必要とするのは正確な内容だ。
- 行番号付きのファイル内容
- 文字列マッチ失敗の理由
- 変更の成功または失敗を表す構造化された結果
ユーザーが必要とするのは、理解可能なフィードバックです。
- どのファイルを読んだか。
- どのファイルを変更したか。
- diff がどのようなものか。
- 拒否されたかどうか。
ソースコード内の FileReadTool の UI 層では、ファイルの内容全体をユーザーインターフェースの検索インデックスに表示することを明示的に避け、モデル側だけが内容を受け取るようになっています。これは、ファイルツールが単に cat の出力をあらゆる場所にそのまま流しているわけではなく、「モデルのコンテキスト」と「ユーザーインターフェース」の間で経路を分けていることを示しています。
2. ファイルツールの全体ツールメニューにおける位置づけ
Claude Code の基本ツール登録エントリポイントは以下の通りです:
src/tools.tsここでファイルツール群が基本ツールリストに登録されます:
FileReadTool
FileEditTool
FileWriteTool
NotebookEditTool検索ツールである GlobTool / GrepTool も同様にここで登録されます。これらとファイルツールは、次のような自然なチェーンを形成します:
まずファイルを探す
-> 次にファイルを読む
-> それからファイルを編集するここで一点補足があります。このソースコードには、独立した LS ツールは存在しません。
Read のプロンプトには、ファイルの読み取りのみを行い、ディレクトリは読み取れないと明記されています。ディレクトリを確認したい場合は、Bash 経由で ls を実行します。また、「パターンに一致するファイルを見つける」ことが目的であれば、Glob を使うことが推奨されます。つまり Claude Code は、ファイル管理を完全な Unix コマンドのミラーとして実装しているのではなく、エージェントにおいて最もよく使われるセマンティクスに沿って切り分けられているのです:
ディレクトリ構造の確認:Bash ls
ファイル名で候補を探す:Glob
内容で候補を探す:Grep
特定ファイルの読み取り:Read
部分的な編集:Edit
作成または全体の書き換え:Writeソースコードのパスは次のように対応します:
src/tools.ts
packages/builtin-tools/src/tools/FileReadTool/FileReadTool.ts
packages/builtin-tools/src/tools/FileEditTool/FileEditTool.ts
packages/builtin-tools/src/tools/FileWriteTool/FileWriteTool.ts
packages/builtin-tools/src/tools/NotebookEditTool/NotebookEditTool.tsTool.ts の観点から見ると、これらはいずれも通常の Tool です。inputSchema、outputSchema、validateInput()、checkPermissions()、call()、UI レンダリング関数をすべて備えています。
しかし、Agent の振る舞いの観点から見ると、それぞれの責務分担は明確です:
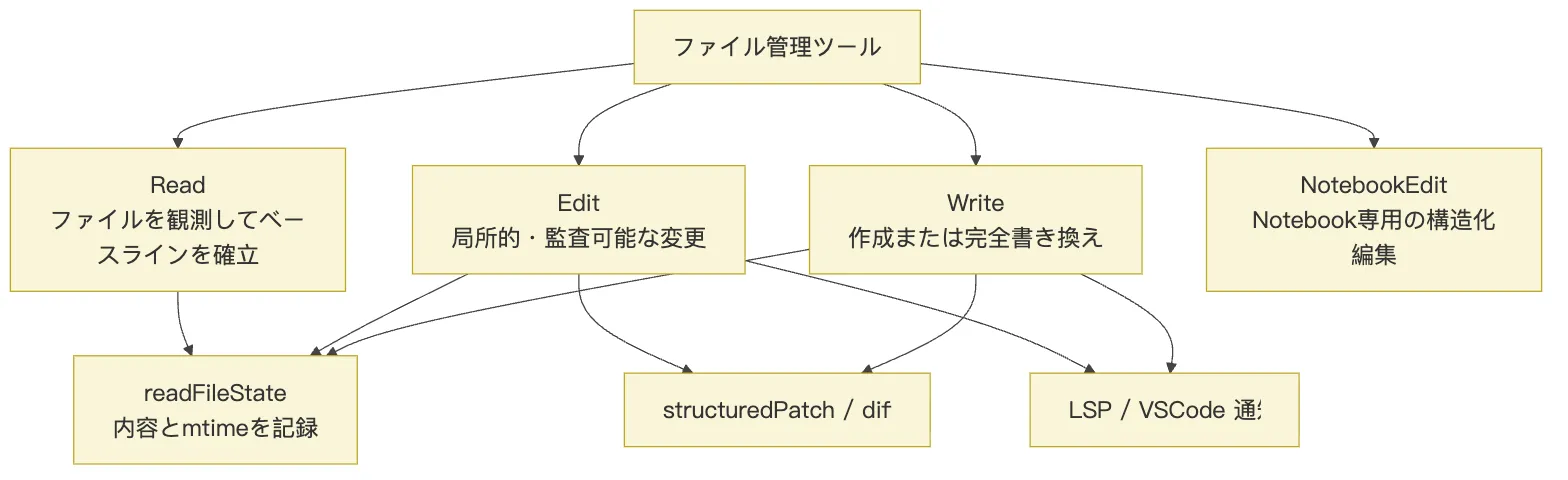
これらは三種類の異なる「ファイル操作セマンティクス」として捉えられます:
Readは観察。Editは観察済み内容に対する部分的な修正。Writeは作成または全体置換。
この三つのセマンティクスが分離されることで、権限、キャッシュ、diff、競合検出に明確な拠り所が生まれます。
3. Read:cat ではなく、ファイルベースラインの確立
Read のエントリポイントは以下です:
packages/builtin-tools/src/tools/FileReadTool/FileReadTool.tsプロンプトは以下にあります:
packages/builtin-tools/src/tools/FileReadTool/prompt.tsRead の入力はシンプルです:
{
file_path: string
offset?: number
limit?: number
pages?: string
}表面的には、パスを読むだけに見えます。ソースコード上で本当に重要なのは次の 3 点です:
- 読み取り専用かつ並行実行可能な正式ツールであること。
- 読み取った内容を
readFileStateに書き込むこと。 - 出力サイズを制御し、ひとつのファイルがコンテキストを圧迫しないようにすること。
1. Read は読み取り専用ツールであり、安全に並行実行できる
FileReadTool の宣言:
isConcurrencySafe() {
return true
}
isReadOnly() {
return true
}
isSearchOrReadCommand() {
return { isSearch: false, isRead: true }
}これは、スケジューラが複数の Read を並行実行できることを示しています。たとえばモデルが 1 ターンで 3 つの関連ファイルを見たい場合:
Read src/auth.ts
Read src/session.ts
Read tests/auth.test.tsこれらのアクションは互いにファイルに書き込まないため、並列実行できます。Edit / Write と比較すると、これは読み取りツールの重要なランタイム特性です。
2. Read はパス、権限、ファイルタイプの検証を行う
validateInput() 内で、Read はまずパスを正規化します:
expandPath(file_path)次に read deny ルールをチェックします:
matchingRuleForInput(fullFilePath, permissionContext, "read", "deny")パスがパーミッション設定によって拒否された場合、ツールはエラーを返し、実際のファイル読み取りには入らない。
見落としがちなセキュリティ上の細かい点をいくつか挙げる:
- Windows の UNC ネットワークパスはファイルシステムの
statをスキップし、パス検証時の SMB/NTLM 認証情報漏洩リスクを回避する。 - 通常のバイナリファイルは拒否されるが、PDF、画像、SVG には個別の処理パスが用意されている。
- 一部のデバイスファイルはブロックされ、読み取り中のハングアップや無限出力を防ぐ。
これが Read が cat ではない理由だ。cat はバイト列を吐き出すだけだが、Read はその読み取りが Agent のコンテキストに取り込むに値するかどうかを判断する。
3. Read のデフォルト最大行数は 2000 行、offset / limit にも対応
FileReadTool/prompt.ts には次のように書かれている:
export const MAX_LINES_TO_READ = 2000デフォルトでは、Read はファイルの先頭から最大 2000 行を読み取る。大きなファイルに対して、モデルは以下のように指定できる:
{
"file_path": "/repo/src/big.ts",
"offset": 1200,
"limit": 200
}これにより、ファイル読み取りは「ページング可能な観測」となり、コンテキストに全内容を一気に詰め込むことはなくなる。
ソースコードにはさらに 2 つの制限が存在する:
maxSizeBytes:デフォルトで総ファイルサイズによる読み取り前制限。maxTokens:デフォルトで出力トークンによる読み取り後制限。
limits.ts では、デフォルトのトークン上限は 25000 となっている。これを超える場合、ツールはモデルに対して offset / limit を使うか、先に具体的な内容を検索するよう促す。
これは Agent にとって極めて重要だ。すべての内容がコンテキストに読み込む価値があるわけではない。ファイルツールはモデルに「まず位置を特定し、次に部分的に読み取る」習慣を身につけさせる役割を担っている。
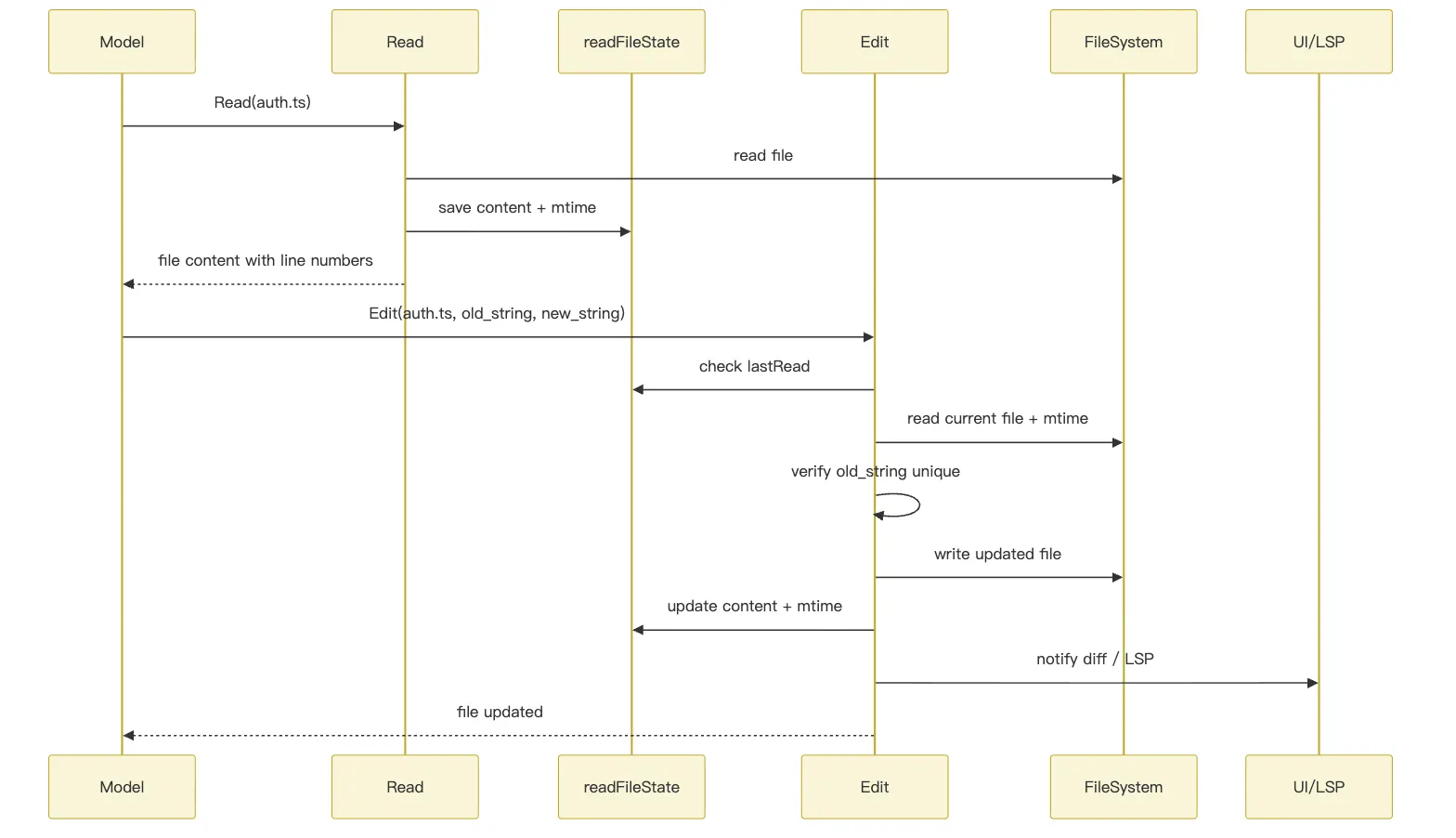
4. Read は内容を readFileState に書き込む
テキスト読み取りの核となる後処理は callInner() 内で行われる:
```text
readFileState.set(fullFilePath, {
content,
timestamp: Math.floor(mtimeMs),
offset,
limit,
})このステップが極めて重要である。
readFileState は、Claude Code が「どのファイルを読んだか、その時の内容は何か、その時の mtime はいつか」をセッションレベルで記録する仕組みと理解するとよい。
後続の Edit / Write はこの記録を参照して次の判断を行う。
このファイルを読み込んだことがあるか?
読み込んだ後、ファイルは変更されたか?
これから書き戻そうとしているベースラインは信頼できるか?つまり Read は単にモデルに内容を見せるだけではない。後続の変更操作のためのベースラインを確立する役割も担っている。
5. 重複読み込みは dedup され、コンテキストの無駄遣いを防ぐ
FileReadTool.call() には読み取りキャッシュの最適化も組み込まれている。
同じファイル・同じ offset / limit で既に読み込み済みであり、
かつファイルの mtime が変わっていない場合、
file_unchanged を返すモデル側に返るのはファイル内容の再送ではなく、次のようなヒントメッセージになる。
File unchanged since last read...この設計思想は実用的だ。直前の Read 結果はまだ対話コンテキスト内に残っているため、同じ内容を再度丸ごと送り込むのはトークンの無駄にしかならない。
4. Edit:自由なファイル編集ではなく、「正確な文字列置換」
Edit のエントリポイントは以下の場所にある。
packages/builtin-tools/src/tools/FileEditTool/FileEditTool.tsプロンプトは以下。
packages/builtin-tools/src/tools/FileEditTool/prompt.tsEdit のコアとなる入力は、patch でも shell でもなく、次の形をとる。
{
file_path: string
old_string: string
new_string: string
replace_all?: boolean
}これは、Claude Code が「部分修正」の抽象化を極めて抑制的に設計していることを示している。
ファイル内のどの旧テキストを、どの新テキストに置き換えるのかを明示せよ。
一見すると不器用な設計だが、Agent には非常によく適合する。
1. 行番号編集を採用しなかった理由
人間はよく「42 行目を変更して」と言う。しかし Agent にとって行番号は本質的に不安定だ。
- ファイルがフォーマットされる可能性がある。
- ユーザーが途中で行を挿入するかもしれない。
- 直前の編集が後続の行番号をずらすかもしれない。
- モデルが
Read出力の行番号プレフィックスをそのままコピーしてしまうかもしれない。
そこで Edit は old_string -> new_string を採用している。
old_string が十分に一意であれば、システムはモデルが記憶した行番号を盲目的に信頼するのではなく、現在のファイル内容から対象を再特定できる。
FileEditTool/prompt.ts でもモデルに次の注意を促している。
Read の出力から内容をコピーする際、行番号プレフィックスを old_string / new_string に含めないこと。言い換えれば、行番号はモデルがファイルを読むための補助であり、編集プロトコルそのものではない。
2. Edit はモデルに事前のファイル読み取りを要求する
Edit のプロンプトには明確にこう記されている。
編集を行う前に、会話の中で少なくとも 1 回は Read ツールを使用しなければならない。実際に実行されると、FileEditTool.call() は次のチェックを行う:
lastRead = readFileState.get(absoluteFilePath)ファイルが存在するにもかかわらず、対応する lastRead がない場合、あるいはファイルの最終更新時刻が前回の読み取り時刻より新しい場合、ツールは次のエラーを送出する:
FILE_UNEXPECTEDLY_MODIFIED_ERRORこれが「読んでから改める」というハードな制約である。
注意すべきは、これは「モデルに必ず先に Read を呼ばせる」という形式的なルールではないということだ。これが実際に保証しようとしているのは次の一点である:
エージェントの変更は、必ず既知のファイルバージョンに基づいていなければならない。このベースラインがなければ、モデルが見ていた内容とディスク上の内容が同じバージョンかどうかを Edit が判断できない。
3. Edit は dirty write を防ぐ
dirty write の問題は、次のような小さなストーリーで説明できる:
10:00 エージェントが auth.ts を読む
10:01 ユーザーが手動で auth.ts を1行修正
10:02 エージェントが 10:00 時点の古い内容をもとに auth.ts をさらに修正ツールがファイルの変化をチェックしなければ、10:01 のユーザーによる修正は上書きされてしまうかもしれない。
FileEditTool.call() の核となるロジックはこうだ:
現在のファイルを読み取り
-> 現在の mtime を取得
-> readFileState から lastRead を探す
-> lastRead がない、または現在の mtime が lastRead.timestamp より新しい場合
-> 内容が本当に変わっていないかさらに比較
-> 内容が変わっていれば、書き込みを拒否これは単に mtime だけを見るよりも慎重なアプローチだ。ソースコードでは Windows やクラウド同期、アンチウイルスソフトなどのシナリオも考慮されている。mtime が変わっていても内容が変わっていないケースがあるからだ。そこで、完全読み取り時に内容の比較を行い、誤った拒否を避けている。
ここにファイルツールのエンジニアリングらしさが表れている。理想化されたルールではなく、現実のファイルシステムが抱える面倒な問題との妥協点を探っているのだ。
4. Edit は old_string の一意性を要求する
validateInput() の中で、Edit はまず実際に置換対象となる文字列を探し出す:
findActualString(file, old_string)見つからない場合は拒否:
String to replace not found in file.見つかったが、マッチ回数が 1 を超え、かつ replace_all が true でない場合も拒否する:
Found N matches of the string to replace, but replace_all is false.このステップは極めて重要である。なぜなら、モデルによくあるミスは「まったく修正できない」ことではなく、短すぎる old_string を与えることだからだ:
return falseこのような文字列はファイル内に何度も出現しうる。システムが場当たり的に最初の一致箇所を置換してしまえば、コードがランダムに書き換わるのと同じである。
そこで Claude Code が取る戦略はこうだ:
十分なコンテキストを与えて old_string を一意にするか、
明示的に replace_all を宣言するか、
さもなくば拒否する。これはモデルに対して「自分がどこを変更したいのか」を表明する責任を負わせることに等しい。
5. Edit はエンコーディングと改行スタイルを保持する
実際に書き込む前に、Edit は readFileForEdit() を呼び出し、以下を取得する:
{
content,
fileExists,
encoding,
lineEndings
}そのうえで writeTextContent() が元のエンコーディングと改行スタイルで書き戻す。
これは人間の読み手には気づきにくいが、コードリポジトリにとっては重要だ。さもなければ、ちょっとした変更のついでにファイル全体の CRLF/LF やエンコーディングスタイルが変わってしまい、diff が膨大になる。
優れたファイルツールとは「書き込める」だけではなく、書くべき箇所だけを書くものでなければならない。
6. Edit は書き込み後にランタイム全体を更新する
Edit は書き込みに成功すると、単に「変更しました」と返すだけではない。以下の一連の後処理を実行する:
structuredPatch の生成
-> writeTextContent でディスクに書き込み
-> LSP に didChange / didSave を通知
-> VSCode に diff ビューの更新を通知
-> readFileState を変更後の内容と mtime で更新
-> ファイル操作の analytics を記録
-> 必要に応じて git diff を計算これは Edit がクロードコードのランタイムの一部であり、独立したファイル関数ではないことを示している。
ファイルがエージェントによって変更されると、後続のシステムすべてがその事実を認識する必要がある。
- LSP は再診断を実行する。
- UI は変更内容を表示できなければならない。
- 次回の編集は新しい内容に基づく必要がある。
- セッション履歴は変更を記録できなければならない。
- リモートモードでは diff の計算が必要になる場合がある。
5. Write:推奨される編集手段ではなく、「新規作成または完全上書き」
Write のエントリポイントは以下にあります。
packages/builtin-tools/src/tools/FileWriteTool/FileWriteTool.tsその入力はより直接的です。
{
file_path: string
content: string
}つまり Write は、毎回ファイル全体を上書きする操作です。
そのため FileWriteTool/prompt.ts はモデルに対して次のように注意を促します。
Prefer the Edit tool for modifying existing files.
Only use this tool to create new files or for complete rewrites.この一文が極めて重要です。
Write はより強力である反面、より危険でもあります。なぜなら、これは部分文字列の置換ではなく、対象ファイルを丸ごと content に置き換えるからです。
1. 既存ファイルであっても、事前に Read が必須
Write のプロンプトには次のように明記されています。
If this is an existing file, you MUST use the Read tool first.実行時には、FileWriteTool.call() も同様の「ダーティライト防止」チェックを行います。
現在のファイルメタを読み取り
-> ファイルが存在する場合
-> readFileState 内の lastRead を検索
-> lastRead がない、またはファイルの mtime が lastRead.timestamp より新しい場合
-> 内容が変更されていないことを証明できないため、書き込みを拒否このように、たとえ完全上書きであっても、Claude Code はモデルが既存ファイルの内容を把握しないまま直接上書きすることを許容しません。
2. Write は create と update を区別する
Write は書き込み完了後、結果を次の二種類で返します。
type: "create"
type: "update"新規ファイルの場合:
originalFile: null
structuredPatch: []既存ファイルを更新する場合:
originalFile: oldContent
structuredPatch: patchつまり Write はファイル全体を上書きする操作でありながら、既存ファイルに対しては diff を生成し、今回の上書きで何が変わったのかをユーザーとシステムに伝える。
3. Write も履歴・LSP・UI に接続される
Edit と同様に、Write は実際の書き込み前に以下を実行する:
fileHistoryTrackEdit(...)
diagnosticTracker.beforeFileEdited(...)書き込み後には:
notifyVscodeFileUpdated(...)
lspManager.changeFile(...)
lspManager.saveFile(...)
readFileState.set(...)このことは、Write が「ファイルを雑に上書きするだけのショートカット」ではなく、よりリスクが高く、限られた場面で使われる正式なツールであることを示している。
Write が適している場面:
- 新規ファイルの作成
- 完全なファイルの生成をユーザーが明示的に要求した場合
- 部分的に書き換えるよりも、ファイル全体を書き直したほうが明快な場合
Write が適さない場面:
- 既存コードの数行だけの修正
- 変数名の変更
- 設定ファイルの特定フィールドだけの変更
- ファイルの中身を読まずにいきなり上書きする操作
6. NotebookEdit:ノートブックに専用ツールが必要な理由
Read は .ipynb を読み取れるが、通常の Edit でノートブックを直接編集することはできない。
FileEditTool.validateInput() では、対象ファイルが .ipynb で終わる場合、次のメッセージが返る。
File is a Jupyter Notebook. Use the NotebookEdit tool to edit this file.理由は単純だ。ノートブックは普通のテキストファイルではない。
.ipynb は表向き JSON だが、実際の編集対象は次の要素である。
- セル(cell)
- セルの種類(cell type)
- ソース(source)
- 出力(outputs)
- メタデータ(metadata)
モデルに通常の文字列置換で .ipynb を編集させると、JSON 構造を破壊したり、セルの出力やメタデータを巻き込んで壊してしまったりする可能性が高い。
そこで Claude Code は、ノートブック編集を NotebookEdit として分離した。ここには、ファイルツール設計における一つの原則が表れている。
ファイルには「バイト列」という単一の意味しかないわけではない。ファイル形式によって、適切な編集粒度は異なる。
通常のソースコードファイルには old_string -> new_string が適している。
ノートブックには「セル単位の編集」が適している。
7. ファイルツールの中核状態:readFileState
ソースコードの概念を一つだけ覚えるとしたら、私は readFileState を選ぶ。
これは ToolUseContext の中で各ツールに渡される。
ToolUseContext.readFileStateRead はここに書き込む。
Edit / Write はここを読み取り、書き込み成功後に更新する。
言うなれば、Claude Code の「ファイル現場記録」だ。
いつ、どのファイルを読んだのか?
そのとき読み取った内容は何か?
そのときのファイルの mtime は?
完全読み取りか、offset / limit による部分読み取りか?これが解決するのは単純なキャッシュではない。Agent プログラミングにおける二つの本質的な問題だ。
1. モデルがファイルを読まずに改変するのを防ぐ
readFileState がない世界では、モデルは平然とこう言える。
{
"file_path": "/repo/src/auth.ts",
"old_string": "return false",
"new_string": "return true"
}しかしシステム側は、そのファイルを本当に読んだのか知る由もない。
readFileState があれば、Edit / Write は最低限こう問える。
このファイルは Read によってベースラインが確立されているか?なければ拒否する。
2. ユーザーや他ツールによる中途変更の上書きを防ぐ
ファイルシステムは共有資源だ。ユーザーも、フォーマッタも、テストスクリプトも、別の Agent も同じファイルを変更しうる。
readFileState があれば、Edit / Write はこう比較できる。
lastRead.timestamp
currentFile.mtime現在のファイルのほうが新しければ、ツールは再読み取りを要求する。
この仕組みによって、Claude Code のファイル変更は「盲目的な書き込み」から「バージョンベースの書き込み」へと変わる。
完全な git merge には及ばず、CRDT(Conflict-free Replicated Data Type。分散システムで結果整合性を実現するデータ構造)でもない。しかし、単一マシンの CLI Agent にとっては、誤上書きのシナリオの大半を防ぐには十分なものだ。
8. 権限:読み取り権限と書き取り権限は別の道
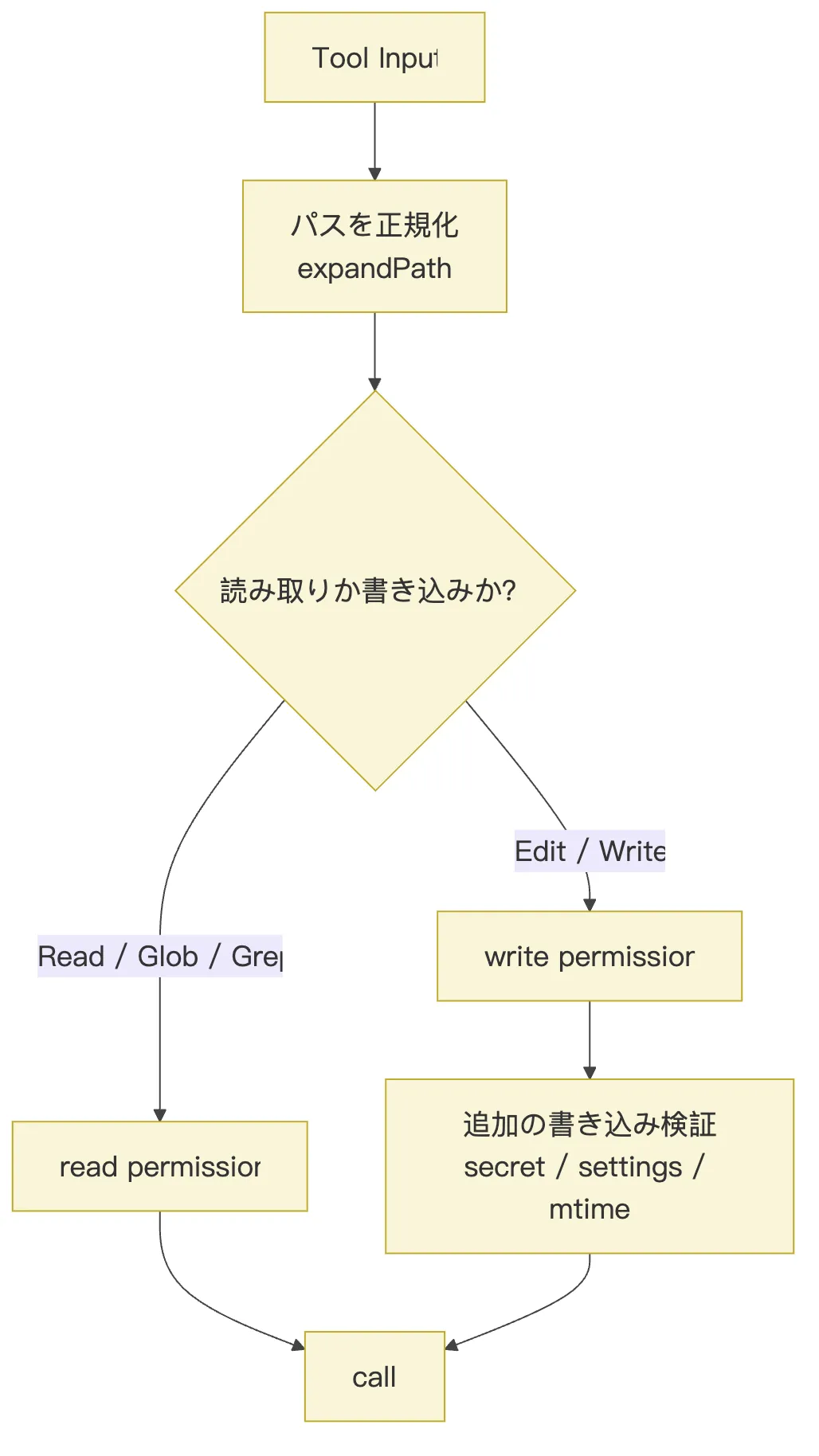
ファイルツールはすべて checkPermissions() に接続されている。
しかし、読み取りと書き取りでは異なる権限セマンティクスを通る:
Read / Glob / Grep -> checkReadPermissionForTool
Edit / Write -> checkWritePermissionForToolこれは非常に理にかなっている。ファイルを読むのと変更するのでは、リスクが異なるからだ。
例えば:
src/auth.tsの読み取りは通常低リスク。src/auth.tsの変更はより高リスク。- シークレットファイルの読み取りも高リスクになりうる。
.claude/settings.jsonのような設定ファイルへの書き込みは追加の検証が必要になる。
Edit と Write はさらに、チームメモリファイルに対してシークレットチェックを行い、機密情報がチームメモリの同期パスに書き込まれるのを防ぐ。
つまり、ファイルツールの権限は単一のオンオフスイッチではなく、アクションのセマンティクスに応じて分割されている:
これこそが専用のファイルツールが必要な理由でもある。すべてを Bash に押し込んでしまうと、権限システムは「そのコマンドが一体何を読み、何を書き込んだのか」を把握するのが非常に難しくなる。
9. 実際の修正から見る完全なリンクチェーン
ここまで説明してきたメカニズムをつなげてみましょう。
ユーザーが次のように言ったとします。
ログイン失敗の問題を修正して。Claude Code はまず検索ツールで対象を特定します。
Glob: **/*auth*.ts
Grep: "login|signIn|authenticate"次に、中心となるファイルを読み込みます。
{
"file_path": "/repo/src/auth.ts"
}このとき Read が内部で行っている処理は次のとおりです。
パス正規化
-> read 権限チェック
-> ファイルタイプ・サイズチェック
-> 内容の読み取り
-> 行番号を付与してモデルに返却
-> readFileState に content / timestamp / offset / limit を記録モデルが問題を特定したら、Edit を使います。
{
"file_path": "/repo/src/auth.ts",
"old_string": "if (!session.user) {\n return false\n}",
"new_string": "if (!session?.user) {\n return false\n}"
}このとき Edit が内部で行っている処理は次のとおりです。
パス正規化
-> write 権限チェック
-> secret / settings / ファイルサイズの検証
-> old_string != new_string の確認
-> 現在のファイルを読み取り
-> readFileState をチェックし、読み取り後の変更がないか確認
-> old_string が存在し、かつ一意であることを確認
-> patch の生成
-> ディスクへの書き込み
-> LSP / VSCode への通知
-> readFileState を変更後の内容に更新
-> 構造化された diff を返却最後に、Claude Code は Bash でテストを実行します。
npm test -- authテストが失敗した場合、新たなエラー出力は ReAct ループ(LLM Agent における推論と行動を交互に繰り返す実行パターン)に戻され、モデルは検索・読み取り・修正・検証を継続します。
この一連の流れで重要なのは「ツールの多さ」ではなく、各ステップが次のステップに対して検証可能な状態を残している点だ。
10. ファイルツールの限界
ファイルツールにも限界はある。
1. Edit は局所的なテキスト編集に向き、複雑なリファクタリングには不向き
Edit の本質は文字列置換である。次のような操作は得意とする:
- ロジックの一部を書き換える。
- 変数名を置換する。
- 分岐を追加する。
- 設定の一部を修正する。
しかし、これは AST(抽象構文木。ソースコードの木構造表現)ベースのリファクタリングツールではない。
ファイル横断的なリネーム、型を考慮したリファクタリング、import の自動修正などになると、Edit だけでは手に余る場面が多い。そうした場合は、検索ツールや LSP ツール、テストのフィードバックと組み合わせて進める必要がある。
2. Write は強力だが、濫用すべきではない
Write はファイル全体を上書きできるため、モデルが安易に手を抜きやすい:
ファイルを読む
-> ファイル全体を再生成する
-> Write で上書きするこれでは diff が大きくなり、細部を取りこぼすリスクも高まる。
そのため、プロンプトでは次のように明示している:
既存ファイルの修正は Edit を優先する。
新規ファイルの作成や完全な書き直しの場合にのみ Write を使う。これも人間のエンジニアリングにおける良い習慣と同じだ。小さな修正で済むなら、大きく置き換えてはならない。
3. readFileState はバージョン管理システムではない
readFileState は典型的なダーティライト(読み取り後の上書き競合)を防ぐ仕組みだが、git の代わりにはならない。
これは現在のセッションにおける読み取りベースラインを記録するものであり、次の役割は担わない:
- ブランチのマージ。
- 複雑なコンフリクトの解決。
- すべての履歴バージョンの追跡。
- 意味レベルでのリファクタリングの把握。
真の長期的なバージョン管理は、やはり git に頼る必要がある。Claude Code のファイルツールが解決するのは、「Agent がこのセッション中に、ファイルの中身をよく見ないまま上書きして壊してしまう」ことを防ぐという課題である。
11. 検索ツールやターミナルツールとの関係
ファイルツールは単独で使われるものではありません。
Claude Code の実際のワークフローでは、ファイルツールは通常、検索ツールやターミナルツールと組み合わさって閉ループを形成します。
Glob / Grep:関連しそうな箇所を見つける
Read:候補ファイルをコンテキストに読み込み、ベースラインを確立する
Edit:局所的で監査可能な変更を加える
Write:新規ファイルの作成、または完全な書き換えを行う
Bash:テスト、ビルド、フォーマット、git コマンドを実行する専用のファイルツールは「コード内容の安全な読み書き」を担当します。
Bash は「プロジェクトコマンドの実行」を担当します。
検索ツールは「大規模リポジトリ内での範囲絞り込み」を担当します。
これら三つの役割を分離することで、システムはそれぞれを最適化できるようになります。
- 検索ツールは結果量を制限し、コンテキストの爆発を防ぎます。
- ファイルツールは読み書きのベースラインを維持し、上書きミスを防ぎます。
- ターミナルツールは長いコマンド、テスト、ビルド、サンドボックスを処理します。
もしすべてを Bash に任せてしまうと、これらの境界はすべて曖昧になってしまいます。
12. この主線を覚えておく
この章は一文に圧縮できる:
Claude Code のファイル管理ツールは、
cat / sed / echoをラップしただけのものではない。「読む・改める・書く」という操作を、検証可能・承認可能・復元可能・表示可能な Agent ファイルワークフローへと昇華させたものだ。
さらに圧縮すると:
Read ベースラインを確立する
Edit ベースラインに基づいて局所置換する
Write 作成または完全上書きのみ行う
readFileState 未読のまま編集したり、読んだ後に他者によって変更された状態で書き続けたりするのを防ぐ
diff / history / LSP / UI 変更を完全なエンジニアリングフィードバックループに乗せるしたがって、Claude Code がなぜエンジニアのようにコードを変更できるのかを見るとき、モデルがコードを書けるかどうかだけを見ていてはいけない。
本当に信頼性を支えているのは、一見すると地味なこれらのファイルツールだ:
- 読まずに変更させない。
- 安易に上書きさせない。
- 曖昧な文字列でやみくもに置換させない。
- 一度の読み取りで過剰なコンテキストを飲み込ませない。
- 一度の書き込みを diff、履歴、診断システムから切り離させない。
Agent の「コードを変更できる」という能力の本質は、一度きりの生成力ではなく、ファイルシステムを中心に構築された一連の工学的規律なのだ。